

Was ist Machine Learning?
Als Machine Learning (ML, dt. Maschinelles Lernen) wird der Zweig der Künstliche Intelligenz (KI) bezeichnet, der sich darauf konzentriert, Daten und Algorithmen zu nutzen, um Wissen generieren und neue Muster und Zusammenhänge erkennen zu können. Es wird also Wissen aus Erfahrungen abgeleitet, so wie es auch wir Menschen tun. Trainierte Systeme können anschließend beispielsweise Vorhersagen treffen, Wahrscheinlichkeiten für bestimmte Ereignisse berechnen oder Prozesse optimieren. Diese Informationen lassen sich anschließend auf andere Datensätze und neue Problemstellungen anwenden, um gleichzeitig die Genauigkeit schrittweise zu verbessern.
Geprägt wurde der Begriff durch die Forschung Arthur Samuels, der 1962 erstmals das Spiel Dame gegen einen IBM 7094 Computer verlor (Quelle). Damit wurde ein Meilenstein in der Geschichte rund um Data Science gelegt, der dazu beigetragen hat, dass heutzutage innovative Technologien wie Empfehlungsfunktionen oder Wetterprognosen zu unserem Alltag gehören.
Aber wie genau setzt sich der ML-Prozess zusammen?
ML kann grob in drei Komponenten unterteilt werden:
- Ein Entscheidungsprozess, in dem mehrschrittige Berechnungen durchgeführt werden, wobei auf Basis der Eingabedaten “geraten” wird, welche Muster entdeckt werden können.
- Eine Fehlerfunktion, welche die erratenen Muster mit bekannten Beispielen (falls vorhanden) vergleicht und die Genauigkeit der Vorhersage auf Basis des aktuellen Entscheidungsprozesses bewertet.
- Ein Modelloptimierungsprozess, in dem der Algorithmus bestimmt, wo Fehler aufgetreten sind und auf Basis dessen das Modell im Entscheidungsprozess aktualisiert wird, damit zukünftig weniger Fehler auftreten. Dieser Prozess wird iterativ durchlaufen, bis ein guter Schwellenwert für die Genauigkeit erreicht ist.
Besser vorstellen kannst du dir den Prozess am Beispiel eines Lieferservice, der dir Gerichte vorschlägt, die dir schmecken könnten. Der zugrundeliegende Algorithmus könnte etwa deine früheren Bestellungen, deine gespeicherten Lieblingsrestaurants oder den prozentualen Anteil an Restaurants, die vegetarisch waren, als Input verwenden. Der Algorithmus wird auf dieser Basis lernen, den richtigen Output zu generieren: Gerichte, die dir schmecken werden. Dafür müssen die richtigen Parameter aus den oben genannten Informationen gewählt und richtig gewichtet werden. Wenn der Algorithmus richtig liegt, werden die Gewichtungen der einzelnen Parameter nicht verändert. Wird jedoch ein falsches Gericht vorgeschlagen, werden die Gewichtungen, die das falsche Ergebnis produziert haben, verändert, damit die Vorhersage in der nächsten Runde verbessert wird. Der ML Algorithmus lernt also aus Erfahrungen durch die Datenanalyse.
Welche Methoden des ML gibt es?
Sogenannte Klassifikatoren des ML können in supervised learning (dt. Überwachtes Lernen), unsupervised learning (dt. Unüberwachtes Lernen), semi-supervised learning (dt. Halbüberwachtes Lernen) und zusätzlich reinforcement learning (dt. Verstärkendes Lernen) unterteilt werden. Worin sie sich unterscheiden, erfährst du im Folgenden.
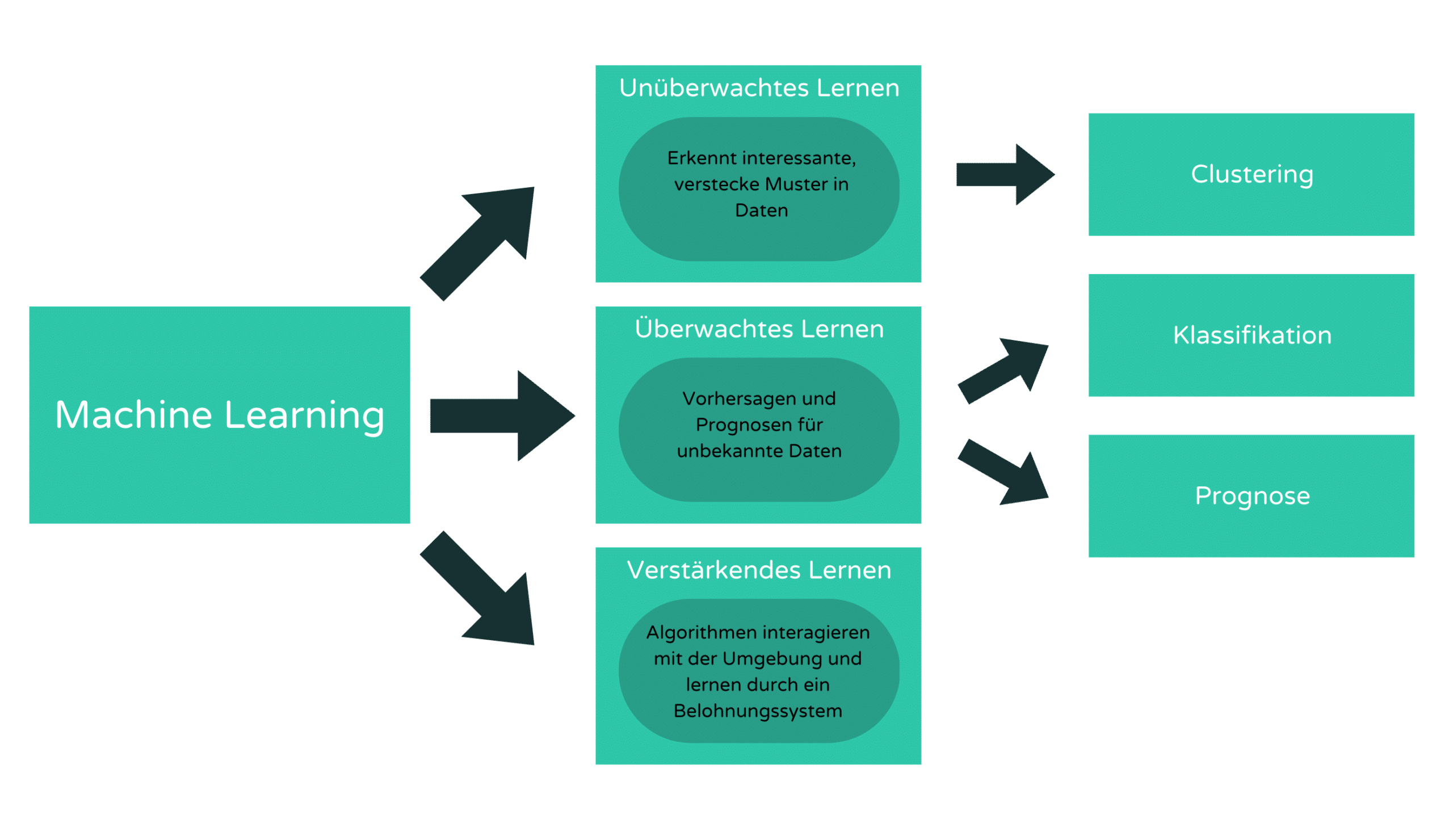 Abbildung 1: Arten von Machine Learning (Quelle: Datasolut)
Abbildung 1: Arten von Machine Learning (Quelle: Datasolut)
Supervised learning
Supervised learning wird dadurch definiert, dass Datensätze vorab von Menschen gelabelt (dt. gekennzeichnet) werden, um Algorithmen zu trainieren, die Daten klassifizieren oder Ergebnisse präzise vorhersagen zu können. Es wird immer der Zusammenhang mit einer Zielvariable gelernt und der Algorithmus soll diese richtig vorhersagen. Eine Zielvariable kann beispielsweise eine binäre Klasse Katze Ja/Nein sein.
Unsupervised learning
Bei dem unsupervised learning hingegen gibt es keine Labels, sondern Daten, aus denen der Algorithmus verdeckte Muster und Gruppen erkennen soll. Ergebnis ist daher keine Vorhersage oder Klassifikation, sondern ein Clustering (dt. eine Gruppierung), das von Data Scientist anschließend bewertet werden muss, um einzuschätzen, wie gut die Ergebnisse zum Kontext passen.
Semi-supervised learning
Semi-supervised learning bezeichnet die goldene Mischung aus den beiden Klassifikatoren. Während des Trainings wird ein kleiner Datensatz mit Labels benutzt, um die Klassifizierung und Merkmalsextraktion anschließend mit einem größeren Datensatz ohne Labels zu ermöglichen, wenn es nicht genügend Daten mit Label gibt.
Reinforcement learning
Als vierte Gruppe der Klassifikatoren gibt es das reinforcement learning wobei mittels trial and error (dt. Versuch und Irrtum) trainiert wird. Eine Folge richtiger Ergebnisse wird belohnt bzw. verstärkt, um daraus die besten Empfehlungen oder Regeln für ein bestimmtes Problem zu entwickeln.
Was ist der Unterschied zu Deep Learning und Neuronalen Netzen?
Da Deep Learning und Machine Learning häufig als Synonyme benutzt werden, möchte ich dir im Folgenden erklären, wie die Begriffe voneinander abgegrenzt werden können.
Am besten veranschaulicht wird die Beziehung von Machine Learning, Deep Learning und Neuronalen Netzen auf der Abbildung 2. Machine Learning gehört zur Künstlichen Intelligenz, Deep Learning ist ein Teil des Machine Learning und Neuronale Netze bilden die Basis für Deep Learning Algorithmen.
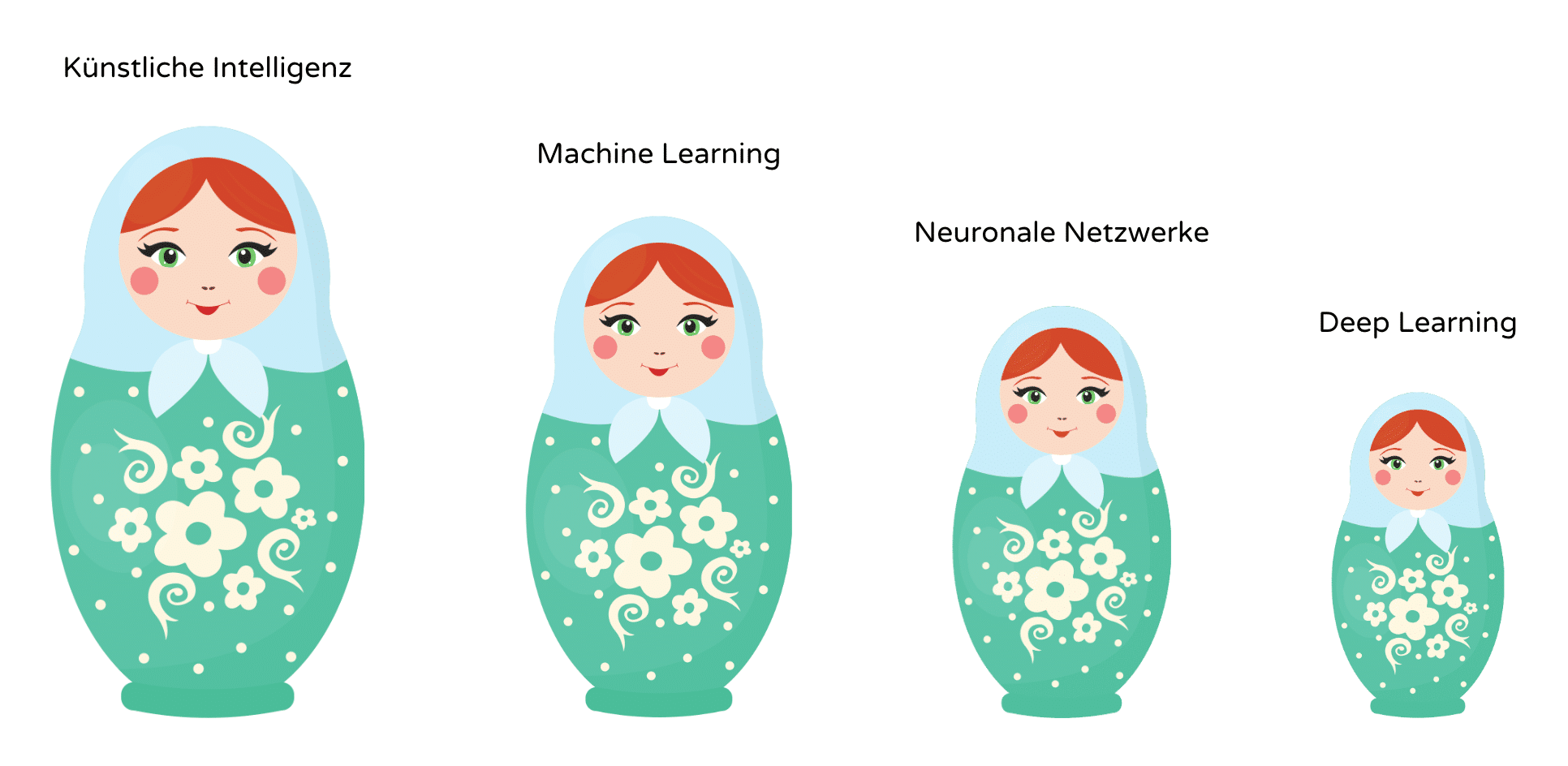 Abbildung 2: Unterschiede von KI, ML, NN und DL (Quelle: IBM)
Abbildung 2: Unterschiede von KI, ML, NN und DL (Quelle: IBM)
Was sind Neuronale Netze?
Neuronale Netze sind angelehnt an die Funktionsweise des menschlichen Gehirns und bestehen aus verschiedenen Layer (dt. Knotenschichten), die sich aus input layer, hidden (dt. verdeckte) layer und output layer zusammensetzen. Die gewichteten Knoten sind miteinander verbunden und können aktiviert werden, um Daten an die nächste layer zu senden. Als Deep (dt. tief) wird ein Neuronales Netz dann bezeichnet, wenn es aus mehr als drei Schichten besteht, also mindestens zwei hidden layers besitzt.
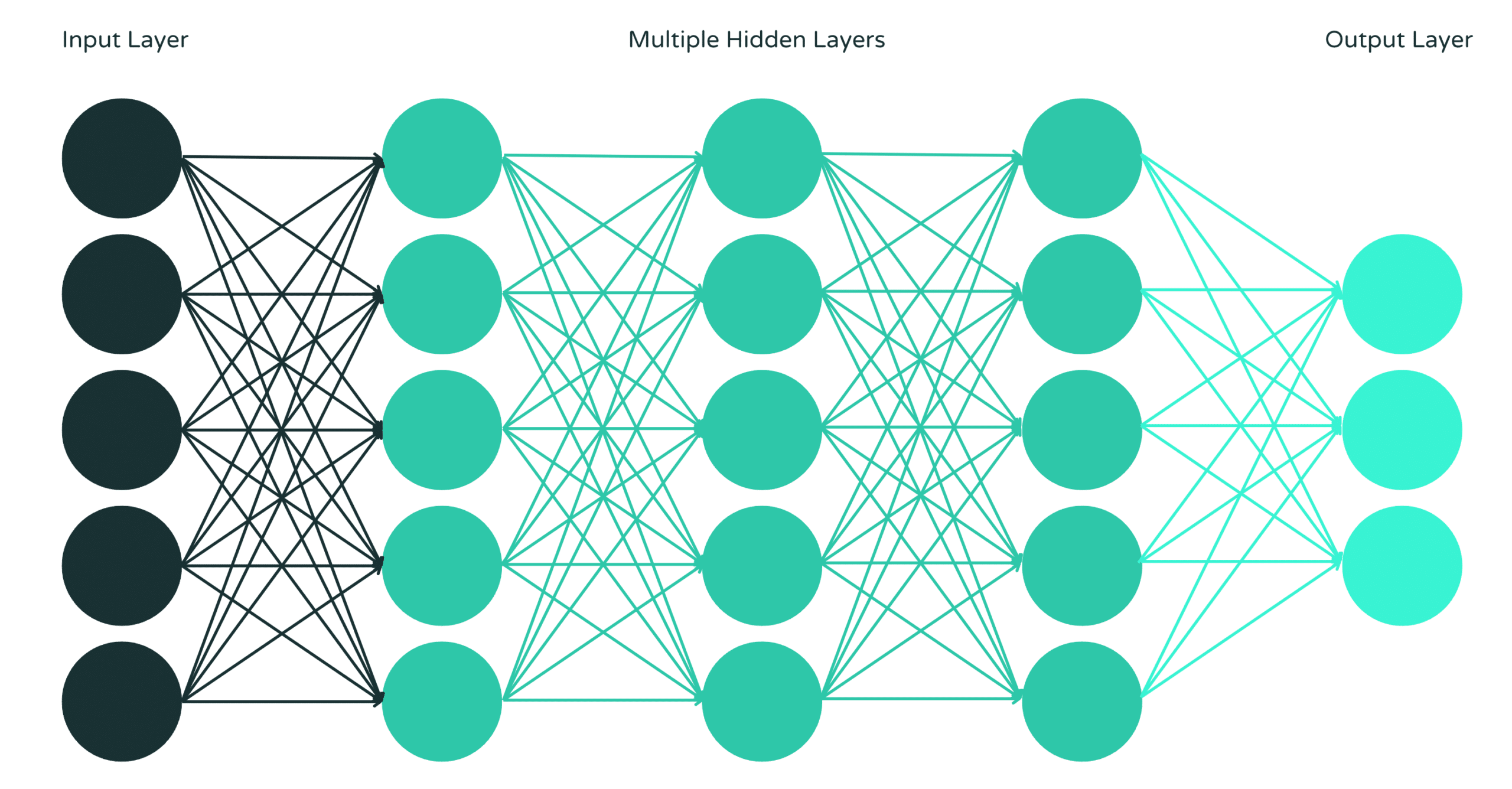 Abbildung 3: Neuronales Netz (Quelle: IBM)
Abbildung 3: Neuronales Netz (Quelle: IBM)
Der wesentliche Unterschied zwischen Deep Learning und Machine Learning liegt also darin, wie der Algorithmus lernt. Da Deep Learning auf neuronalen Netzen basiert, wird die Merkmalsextraktion weitestgehend automatisiert, weshalb kaum menschliche Arbeit benötigt wird und riesige unstrukturierte, rohe Datensätze verarbeitet werden können. Unstrukturierte Daten wie Bilder, Texte oder Videos können in numerische Werte umgewandelt werden, die dann zur Mustererkennung, Vorhersage oder zum weiteren Lernen verwendet werden können.
Wenn du neugierig geworden bist und dich fragst welche Methoden des Machine Learning in welchen Anwendungsszenarien genutzt werden, dann bietet dir Abbildung 4 einen kleinen Überblick.
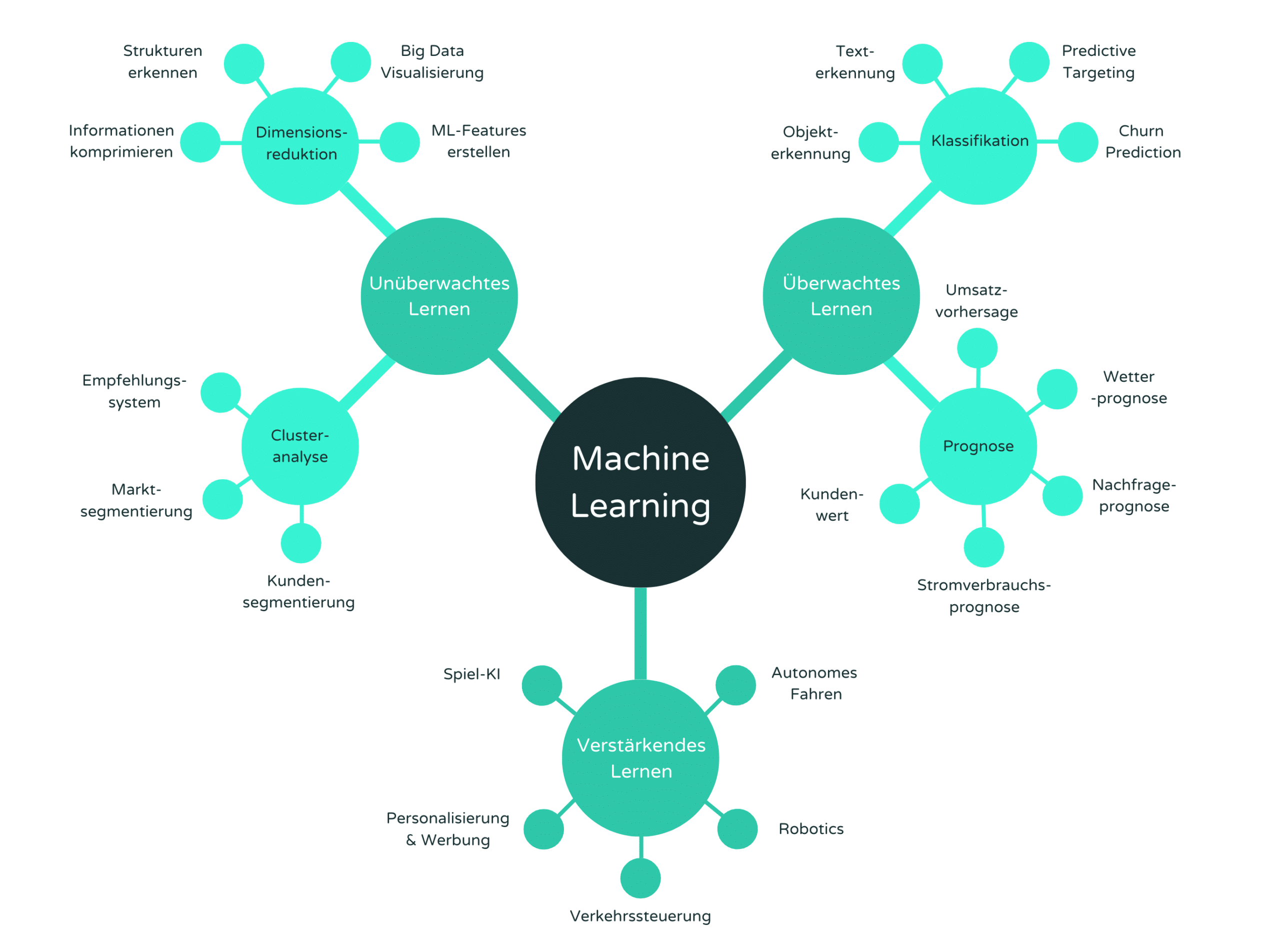 Abbildung 4: Anwendungsszenarien (Quelle: Datasolut)
Abbildung 4: Anwendungsszenarien (Quelle: Datasolut)
Auch wenn Machine Learning noch vor einigen Herausforderungen wie etwa fehlenden Regulierungen, intransparenten Algorithmen oder Bias steht, ist klar: Machine Learning ist nicht mehr wegzudenken, sondern wird zukünftig immer mehr an Bedeutung gewinnen und unser aller Leben begleiten.