

Vielleicht hast du schon einmal davon gehört, dass bestimmte KI-basierte Systeme, immer wieder fehlerhafte Entscheidungen treffen, die diskriminierend und unfair sind? Insbesondere, da KI immer häufiger in Bereichen eingesetzt wird, in denen wichtige Entscheidungen getroffen werden, ist es wichtig, Probleme dieser Art zu adressieren. Daher möchte ich dir in diesem Artikel einen Einstieg in die Diskussion rund um Fairness und Bias von KI ermöglichen, damit du die Zukunft informiert mitgestalten kannst.
Willst du vorher wissen, was genau KI ist und kann? Dann schau hier vorbei: Künstliche Intelligenz
Was ist eigentlich Bias?
Ins Deutsche übersetzt bedeutet Bias Verzerrungseffekt. Eine einheitliche Definition gibt es jedoch nicht. In der Psychologie beschreibt Bias menschliche Wahrnehmung, Handlungen und Entscheidungen, die durch bestimmte Meinungen, Haltungen oder Stereotypen beeinflusst oder verzerrt werden. Es wurden mittlerweile über 180 Arten von Bias gefunden.
In der Statistik hingegen wird Bias als fehlerhafte Datenerhebung oder -verarbeitung beschrieben.
Was bedeutet das für KI-Systeme?
Geht es um Machine Learning (ML) und algorithmische Entscheidungen wird häufig angenommen, dass diese neutraler und objektiver wären, da die Merkmale nach bestimmten Regeln verarbeitet werden. Dies ist jedoch häufig ein Trugschluss, denn Bias kann in jeder Phase des ML-Lebenszyklus entstehen, wie ich dir im Folgenden beschrieben habe. Eine Übersicht davon, wo Bias im ML-Lebenszyklus entstehen kann und welche Arten es gibt findest du in Abbildung 1.
Bias in der Datenerhebung und WEIRD samples
Angefangen bei der Datenerhebung, kann etwa eine verzerrte, unrepräsentative Stichprobe der definierten Zielpopulation Bias in das System einführen. Werden ML-Algorithmen mit Datensätzen trainiert und getestet, die unvollständig sind, die reale Welt nicht umfangreich genug abdecken oder bereits diskriminierende Daten beinhalten, so besteht die Gefahr, dass diese Systeme unter realen Bedingungen, für andere Datensätze schlechtere Ergebnisse erzielen, falsche Vorhersagen und somit diskriminierende Entscheidungen treffen. Verzerrte Trainingsdaten werden in Bezug auf ihre Zusammensetzung, auch als WEIRD Samples (western, educated, industrialized, rich and democratic societies) bezeichnet.
So erkennen zum Beispiel einige Systeme zur Gesichtserkennung die Gesichter von schwarzen Frauen signifikant schlechter, da das Modell auf Datensätzen basiert, die überwiegend weiße, männliche Gesichter abbilden.
Was ist ein Feedback Loop?
Eine zusätzliche Herausforderung besteht außerdem darin, dass solch verzerrte KI- Entscheidungsprozesse oft zyklisch sind, wenn der Bias nicht rechtzeitig identifiziert wird, auch bekannt als Rückkopplungsschleife (engl. feedback loop). Das bedeutet, dass die Entscheidungen der KI-Systeme den Zustand der Welt beeinflussen, der bei der nächsten Datenerhebung vorliegt. Ein anschauliches Beispiel für Modelle, die diskriminierende gesellschaftliche Strukturen zyklisch reproduzieren, betrifft den Tech-Konzern Amazon. Dieser hat im Jahr 2018 versucht, eine KI-Anwendung zu entwickeln, die den Einstellungsprozess unterstützen sollte, indem Kandidatinnen automatisiert ausgewählt werden. Dabei wurde das System mit historischen Daten von Amazon Mitarbeiterinnen trainiert und getestet. Diese bestanden jedoch zu diesem Zeitpunkt, aufgrund der Gender Gap in der IT, aus überwiegend weißen und männlichen Personen. Folglich wurde das System unbeabsichtigt darauf trainiert, Bewerbungen von Männern zu präferieren und die von Frauen abzulehnen.
Glücklicherweise wurde dieser sexistisch diskriminierende Bias aufgedeckt, sodass das System abgeschaltet werden musste. Stell dir jedoch vor, er wäre nicht entdeckt worden, dann wird dir schnell klar, dass es sich in dem Fall um einen zyklischen Prozess handeln würde. Amazon würde weiterhin überwiegend Männer einstellen und diese Daten nutzen, um das KI-System weiter zu trainieren.
Kognitiver Bias und Design
Bias entsteht jedoch nicht nur durch verzerrte Daten. Auch das Design und die Entwicklung und die Evaluation der Modelle bestimmen maßgeblich, wie KI-Anwendungen Entscheidungen treffen. Häufig sind es unbewusste Entscheidungen von Entwickler*innen und Designer*innen, die das System verzerren, bekannt als kognitiver Bias. So etwa haben Entwickler*innen einen automatisierten Seifenspender so programmiert, dass dieser aktiviert wird, sobald eine helle Fläche (die Hand) wahrgenommen wird. Jedoch wurde dabei nicht bedacht, dass dies zu einem Problem für PoC führen könnte, da der Seifenspender ihre Hände nicht erkennen konnte.
Dies ist einerseits darauf zurückzuführen, dass sich die Entwickler*innen über ihre verzerrte Wahrnehmung nicht bewusst waren und lediglich versucht haben die Komplexität der Welt in einem simplen Algorithmus abzubilden, andererseits spiegelt dieses Beispiel die Relevanz von Diversität in der IT wider.
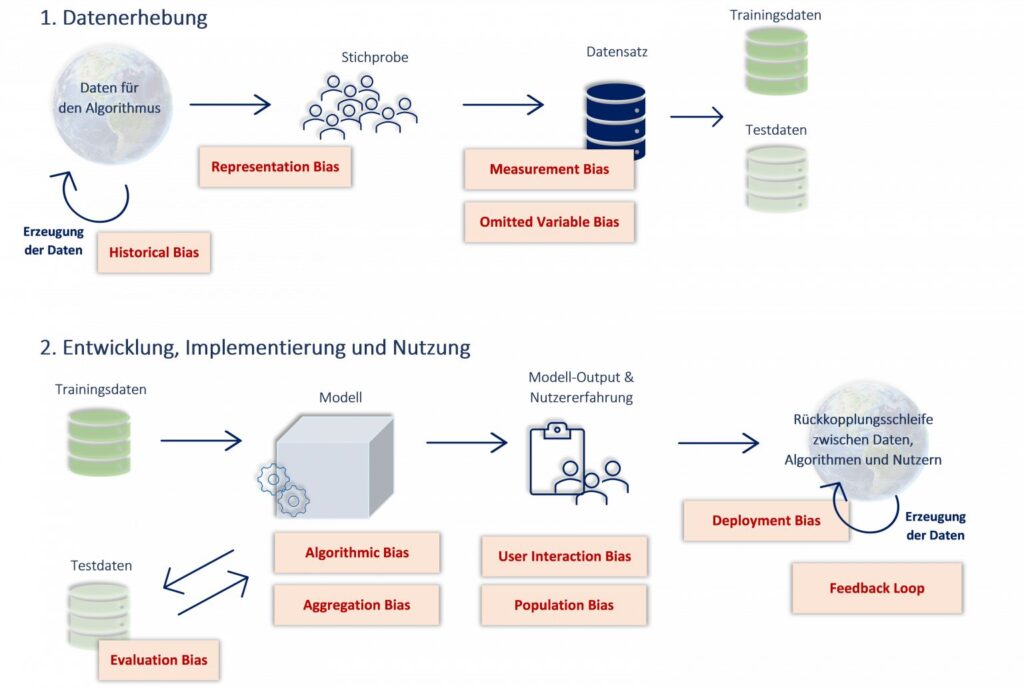 Abbildung 1 (Quelle: Institut für Business Analytics)
Abbildung 1 (Quelle: Institut für Business Analytics)
Ist KI ohne Bias möglich?
Die Antwort ist, theoretisch ja. Eine KI-Anwendung kann nur so gut sein, wie die Qualität der verwendeten Daten. Würden aus den Trainings- und Testdaten sämtliche (un)bewusste Voreingenommenheiten und verzerrte Konzepte entfernt werden, so wäre es möglich, KI zu entwickeln, die datenbasierte Entscheidungen ohne Bias trifft.
In der realen Welt, wie wir sie heute kennen, halten es Expert*innen jedoch für unwahrscheinlich, dass KI jemals ganz frei von Bias sein wird. Eben aus genau jenem Argument, dass KI nur so gut sein kann, wie die verwendeten Daten. Wie bereits erwähnt, ist die menschliche Wahrnehmung nie ganz frei von kognitiven Bias. Menschen formen gesellschaftliche Strukturen und Wahrnehmungen und betten diese in Form von Daten in Technologien ein. Dies ist jedoch häufig leider nicht so offensichtlich wie in den bereits genannten Beispielen. Umso mehr Bedarf besteht, die Herausforderungen in der Nutzung und Entwicklung von KI-Systemen zu verstehen und Lösungskonzepte auszuarbeiten. Einige Ansätze existieren bereits.
Wie kann Bias in KI entgegengewirkt werden?
Leider gibt es keine einfache und schnelle Lösung, Bias aus Technologien zu entfernen. Jedoch gibt es Best Practices und Leitlinien, die uns dem Ziel ein Stück näher bringen können.
Darunter zählt die Analyse von Risiken, wo Bias im ML-Zyklus auftreten könnte. Ein kritisches Hinterfragen von Voreingenommenheiten und gesellschaftlichen Strukturen kann helfen, Bias aufzudecken und rechtzeitig abzufangen. Da das Thema Fairness, Bias und Responsible AI immer mehr an Bedeutung gewinnt, gibt es außerdem bereits Algorithmen und Tools, die helfen sollen, Bias zu minimieren. Dazu zählt beispielsweise das von IBM entwickelte AI Fairness 360 Tool zur Erkennung und Reduktion von Bias in Algorithmen. Jedoch ist der Bereich der algorithmischen Fairness noch jung und bedarf weiterer Lösungsansätze und interdisziplinärer Forschung.
Darüber hinaus spielt, wie bereits angedeutet, die intersektionale Diversität im Team eine entscheidende Rolle für faire KI-Anwendungen. Dazu sollte das Team im Hinblick auf möglichst viele Aspekte, wie beispielsweise Gender, Herkunft, Bildungsweg, Erfahrung oder Expertise, divers sein. Je mehr Perspektiven in die Entwicklung von Technologien einfließen, umso höher ist die Wahrscheinlichkeit, Bias abschwächen zu können.
Also ein Grund mehr dich für die IT zu entscheiden und aktiv an der Gestaltung einer fairen und gleichberechtigten Zukunft mitzuwirken, in der Technologie Mehrwert für alle schafft!
Für mehr spannende Informationen und News folge uns auf Instagram und LinkedIn.